



























Written by Josip Rozman
Senior Consultant
Human Problem Solving in the AI-era
Science fiction has long played with the idea of a creative, and mostly benevolent AI which would be able to produce innovative works of literature and art of the highest quality.
The hype is partially to blame for our extremely high expectations of said models, and to a degree of disappointment when our expectations are not completely met. There are currently two big areas of research for generative models: natural language and image (video).
Regarding natural language models the trend started with large language models such as the GPT family producing text sequences. Some of the notable examples include AI powered chat bots, an interactive Dungeons and Dragons prompt, and code writing AI (hence I am writing blogs now).
The second trend is the AI image generation and the topic I would like to focus a bit more on in this blog. The trend started with models such as Generative Adversarial Networks (GAN-s) and Variational Autoencoders (VAE-s) which produced some high-quality images, but they were limited in what they could achieve. The main limitation of these models was the need to train the model on only a single type of data such as human faces, and the model would only be able to output an image in the said domain. But let’s stop at GAN-s for a second, a GAN in its original form takes random noise and produces an output in a single step which is a complex task for the model to learn and can lead to many difficulties in training and suboptimal outputs. We have explored the use of GAN-s in the past for removal of Windfarm clutter in Radar imagery with a good level of success.
The true revolution came in the form of multimodal models, models which combine multiple modalities. In this case I am referring to models such as DALL-E and its less known relative CLIP, where DALL-E could generate images grounded in a text prompt while CLIP would be used to order how good the generated images are in regard to the prompt. There were some shortcomings of DALL-E such as the compute required due to being Transformer based, but future work would refine the idea further, bringing us to Diffusion models.
Diffusion models work on a simple but powerful idea. It is hard to make something out of nothing, as alchemist have discovered through the ages. The problem is rephrasing as removing small amounts of noise iteratively. There is a bit more to it than that, but that is the main idea. The model is supplied with a random noise seed which it is progressively asked to remove (the model does not attempt to predict the image without the noise, but the noise itself and it is removed from the image), all the while being grounded with a text prompt. The idea can then be extended to videos, but more work is required in this area before we will be able to see AI generated blockbusters (https://makeavideo.studio/).
Could this technique be used in any way for hardware design? Previously we have employed AI techniques with success for task such as a heatsink design. Now the question would be could multimodal models in the future be used to produce designs from our specifications? The image bellow uses Stable Diffusion 2 (https://huggingface.co/spaces/stabilityai/stable-diffusion) for the prompt:
“A radar blueprint with 3 transmitter and 4 receiver antennas CAD model”.
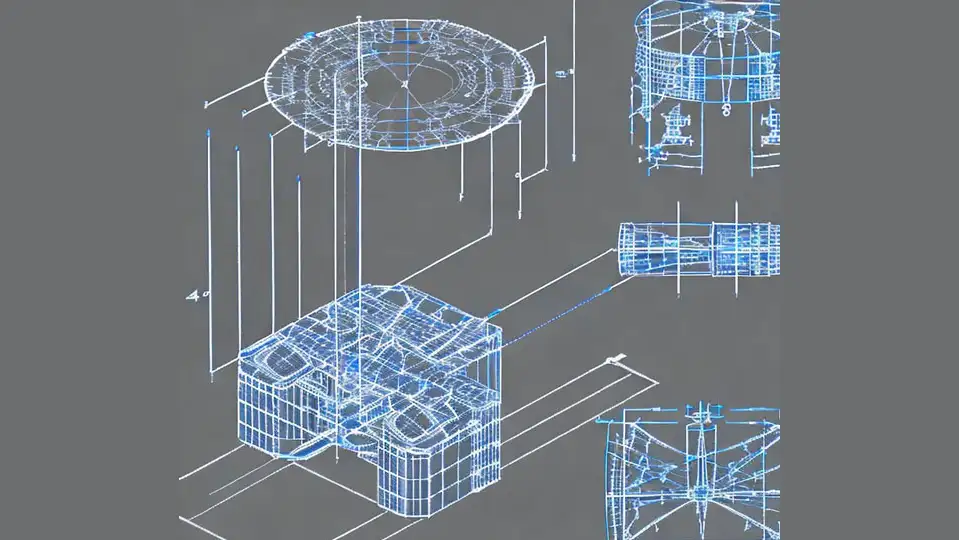
Could this prompt be improved with ChatGPT? If we ask ChatGPT to suggest a prompt which would result with a high-quality image for our previous prompt it recommends:
“Generate a high-quality CAD model of a radar blueprint featuring 3 transmitter and 4 receiver antennas, rendered in accurate detail and clearly labelled.”
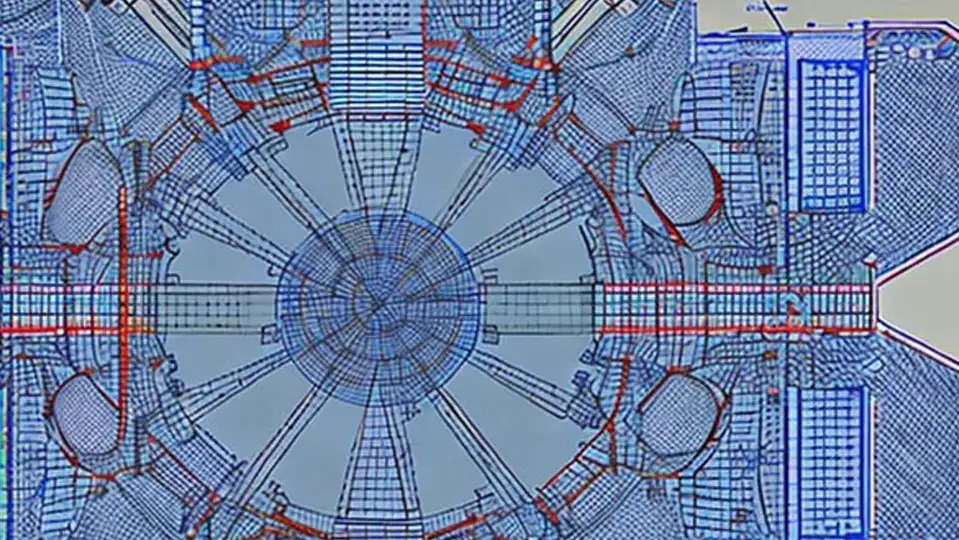
While visually impressive I still do not think we are there, yet! But I look forward to seeing what the future would bring. Now it is over to you. Do you see any potential in using such multimodal models? Would there be any benefits of using additional modalities such as audio/RF?
Please let us know your opinions, and if we could use any of these techniques to help with some of your challenges?


Contact Us
Technology Platforms
Plextek's 'white-label' technology platforms allow you to accelerate product development, streamline efficiencies, and access our extensive R&D expertise to suit your project needs.
- 01 Configurable mmWave Radar Module
 Configurable mmWave Radar Module
Configurable mmWave Radar ModulePlextek’s PLX-T60 platform enables rapid development and deployment of custom mmWave radar solutions at scale and pace
- 02 Configurable IoT Framework
 Configurable IoT Framework
Configurable IoT FrameworkPlextek’s IoT framework enables rapid development and deployment of custom IoT solutions, particularly those requiring extended operation on battery power
- 03 Ubiquitous Radar
 Ubiquitous Radar
Ubiquitous RadarPlextek's Ubiquitous Radar will detect returns from many directions simultaneously and accurately, differentiating between drones and birds, and even determining the size and type of drone

Enhancing communication and safety in mining: the role of custom RF system design
We explore the role of custom RF system design in communication and safety within the mining industry, ensuring robust data handling and operational efficiency in challenging conditions.

Continuing to Lead in Radar Development for Pioneering CLEAR Mission
We continue to advance radar technology for the CLEAR mission, reinforcing the partnership with ClearSpace and the UK Space Agency for sustainable space safety and debris removal.

Revolutionising chronic pain management
Fusing mmWave technology and healthcare innovation to devise a ground-breaking, non-invasive pain management solution, demonstrating our commitment to advancing healthtech.

Pioneering Advanced In-Orbit Servicing
Pioneering a ground-breaking collaboration in advanced in-orbit servicing, setting new benchmarks for space debris removal and satellite maintenance.

SSL: The Revolution Will Not Be Supervised
Exploring the cutting-edge possibilities of Self-Supervised Learning (SSL) in machine learning architectures, revealing new potential for automatic feature learning without labelled datasets in niche and under-represented domains.

Unlocking the mysteries of imaging radar data processing
Looking deeper into the cutting edge of imaging radar data processing, where innovative techniques and practical applications combine to drive forward solutions.

Evolving silicon choices in the AI age
How do you choose? We explore the complexities and evolution of processing silicon choices in the AI era, from CPUs and GPUs to the rise of TPUs and NPUs for efficient artificial intelligence model implementation.

Advancing space technology solutions through innovation
At the forefront of space technology innovation, we address complex engineering challenges in the sector, delivering low size, weight, and power solutions tailored for the harsh environment of space.

A Programmer’s Introduction to Processing Imaging Radar Data
A practical guide for programmers on processing imaging radar data, featuring example Python code and a detailed exploration of a millimetre-wave radar's data processing pipeline.

Folded Antennas; An Important Point of Clarification
Exploring the essential nuances of folded antennas, ensuring precision and clarity in this critical aspect of RF engineering and design.

Innovation Strategies in Times of Scarcity
In scenarios where scarcity reshapes the business landscape—where customers are limited or prohibited from accessing stores and bars, supply chains are fragmented, and financial instability is rampant—how can innovation move forward?

Running engineering projects sustainably
Outlining how sustainable practices were integrated into engineering projects, covering all ESG (Environmental, Social, Governance) aspects from reducing economic inequality to combating climate change.
Downloads
View All Downloads- Intro to Plextek
- Plextek – Your complete end-to-end solution
- PLX-T60 Configurable mmWave Radar Module
- PLX-U16 Ubiquitous Radar
- Configurable IOT Framework
- MISPEC
- Cost Effective mmWave Radar Devices
- Connected Autonomous Mobility
- Antenna Design Services
- Drone Sensor Solutions for UAV & Counter-UAV Awareness
- mmWave Sense & Avoid Radar for UAVs
- Exceptional technology for marine operations

Harsh Environment Inductive Coupling Solutions for Emerson
Discover how our technical expertise in inductive coupling facilitated Emerson in setting industry benchmarks for efficiency and reliability in harsh environments.
Read More
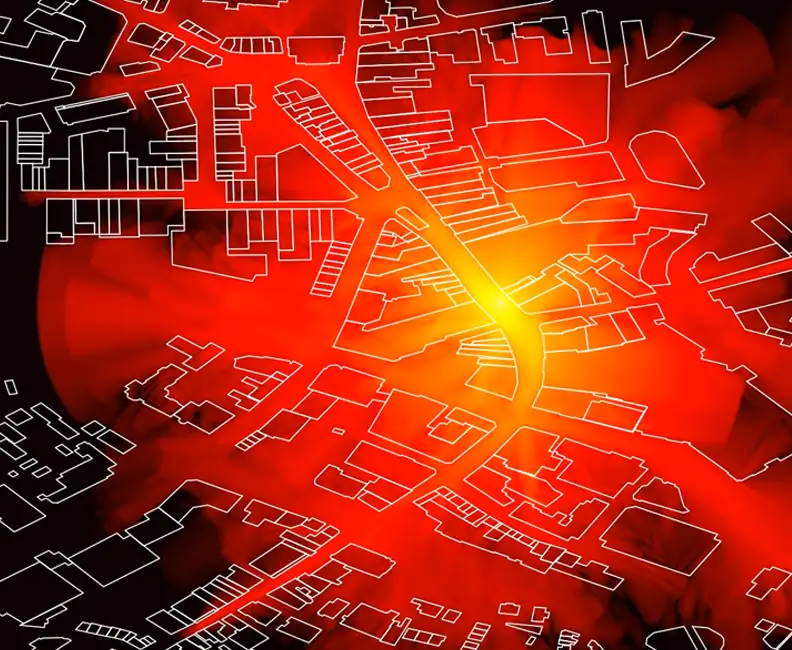
Machine Learning for Rapid Propagation Assessment
Developing a groundbreaking ML model for swift and efficient coverage prediction in complex urban environments, enabling rapid optimisation of transmitter locations on standard computing hardware.
Read More

Cost-Effective Improvement in mmWave Intensity
Enhancing the mmWave antenna design for Remedee Labs, significantly boosting RF radiation efficiency and cost-effectiveness in non-pharmaceutical chronic pain treatment.
Read More

Game-Changing Radar for the CLEAR Mission
Developing vital radar technology for the CLEAR mission, advancing space debris removal techniques to safeguard operational satellites and spacecraft.
Read More

Future Sensing: Improving Mobile Ad-hoc Networks
Leading a transformative four-year research initiative to improve mobile ad-hoc networks through advanced directional antenna systems and cross-layer processing, significantly enhancing military communication capabilities.
Read More

Millimetre-Wave Radar System
Expertly engineering a compact, high-performance 60 GHz millimetre-wave radar system using innovative Substrate Integrated Waveguide technology, achieving significant advancements in target detection up to 100 metres.
Read More

Communicating Across Surfaces
Using innovative expertise in metamaterials to facilitate the development of advanced surfaces, improving RF communication efficiency through pioneering surface wave technology for superior antenna design and wireless connectivity.
Read More

Armour Integrity Monitoring System (AIMS)
Innovating a new Armour Integrity Monitoring System (AIMS) for the UK MoD, delivering a low SWaP-C solution that dramatically streamlines logistics and enhances protection through in-field armour integrity checks.
Read More

mmWave Radar for Foreign Object Debris Detection
Collaborating with WaveTech to develop an advanced mmWave radar system, enabling the rapid and automated detection of foreign object debris on runways, enhancing safety and operational efficiency at a South Korean airport.
Read More
Spinbrush: From Insights to Strategy to Design
Discover how we enabled Spinbrush to leverage consumer insights to innovate and excel in the competitive powered toothbrush market with our strategic approach.
Read More

Energenie Smart Home Controller
Redesigning the Energenie Smart Home Controller interface to introduce low-power radio technology, enhancing device functionality for centralised home heating control, and launching nationwide.
Read More

Developing Automated Manufacturing Systems
Delivering a pioneering predictive maintenance solution for a global healthcare product company, utilising miniature battery-powered sensor systems to optimise automated production lines and significantly reduce costly downtimes.
Read More

mmWave Imaging Radar
Camera systems are in widespread use as sensors that provide information about the surrounding environment. But this can struggle with image interpretation in complex scenarios. In contrast, mmWave radar technology offers a more straightforward view of the geometry and motion of objects, making it valuable for applications like autonomous vehicles, where radar aids in mapping surroundings and detecting obstacles. Radar’s ability to provide direct 3D location data and motion detection through Doppler effects is advantageous, though traditionally expensive and bulky. Advances in SiGe device integration are producing more compact and cost-effective radar solutions. Plextek aims to develop mm-wave radar prototypes that balance cost, size, weight, power, and real-time data processing for diverse applications, including autonomous vehicles, human-computer interfaces, transport systems, and building security.

Low Cost Millimeter Wave Radio frequency Sensors
This paper presents a range of novel low-cost millimeter-wave radio-frequency sensors that have been developed using the latest advances in commercially available electronic chip-sets. The recent emergence of low-cost, single chip silicon germanium transceiver modules combined with license exempt usage bands is creating a new area in which sensors can be developed. Three example systems using this technology are discussed, including: gas spectroscopy at stand off distances, non-invasive dielectric material characterization and high performance micro radar.
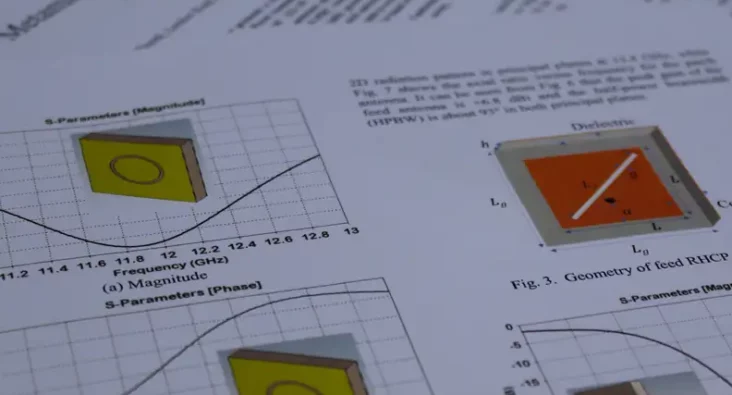
Ku-Band Metamaterial Flat-Panel Antenna for Satcom
This technical paper by Dr. Rabbani and his team presents research on metamaterial-based, high-gain, flat-panel antennas for Ku-band satellite communications. The study focuses on leveraging the unique electromagnetic properties of metamaterials to enhance the performance of flat-panel antenna designs, aiming for compact structures with high gain and efficiency. The research outlines the design methodology involving multi-layer metasurfaces and leaky-wave antennas to achieve a compact antenna system with a realised gain greater than +20 dBi and an operational bandwidth of 200 MHz. Simulations results confirm the antenna's high efficiency and performance within the specified Ku-band frequency range. Significant findings include the antenna's potential for application in low-cost satellite communication systems and its capabilities for THz spectrum operations through design modifications. The paper provides a detailed technical roadmap of the design process, supported by diagrams, simulation results, and references to prior work in the field. This paper contributes to the advancement of antenna technology and metamaterial applications in satellite communications, offering valuable insights for researchers and professionals in telecommunications.

The Kootwijk VLF Antenna: A Numerical Model
A comprehensive analysis of the historical Kootwijk VLF (Very Low Frequency, which covers 3-30 kHz) antenna, including the development of a numerical model to gain insight into its operation. The Kootwijk VLF antenna played a significant role in long-range communication during the early 20th century. The paper addresses the challenge of accurately modelling this electrically small antenna due to limited historical technical information and its complex design. The main goal is to understand if the antenna’s radiation efficiency might explain why “results were disappointing” for the Kootwijk to Malabar (Indonesia) communications link. Through simulations and comparisons with historical records, the numerical model reveals that the Kootwijk VLF antenna had a low radiation efficiency – about 8.9% – for such a long-distance link. This work discusses additional loss mechanisms in the antenna system that might not have been considered previously, including increased transmission-line losses as a result of impedance mismatch, wires having a lower effective conductivity than copper and inductor quality factors being lower than expected. The study provides insights into key antenna parameters, such as the radiation pattern, the antenna’s quality factor, half-power bandwidth and effective height, as well as the radiated power level and the power lost through dissipation. This research presents the first documented numerical analysis of the Kootwijk VLF antenna and contributes to a better understanding of its historical performance. While the focus has been at VLF, this work can aid future modelling efforts for electrically small antennas at other frequency bands.

The Radiation Resistance of Folded Antennas
This technical paper highlights the ambiguity in the antenna technical literature regarding the radiation resistance of folded antennas, such as the half-wave folded dipole (or quarter-wave folded monopole), electrically small self-resonant folded antennas and multiple-tuned antennas. The feed-point impedance of a folded antenna is increased over that of a single-element antenna but does this increase equate to an increase in the antenna’s radiation resistance or does the radiation resistance remain effectively the same and the increase in feed-point impedance is due to transformer action? Through theoretical analysis and numerical simulations, this study shows that the radiation resistance of a folded antenna is effectively the same as its single-element counterpart. This technical paper serves as an important point of clarification in the field of folded antennas. It also showcases Plextek's expertise in antenna theory and technologies. Practitioners in the antenna design field will find valuable information in this paper, contributing to a deeper understanding of folded antennas.

Chilton Ionosonde Data & HF NVIS Predictions during Solar Cycle 23
This paper presents a comparison of Chilton ionosonde critical frequency measurements against vertical-incidence HF propagation predictions using ASAPS (Advanced Stand Alone Prediction System) and VOACAP (Voice of America Coverage Analysis Program). This analysis covers the time period from 1996 to 2010 (thereby covering solar cycle 23) and was carried out in the context of UK-centric near-vertical incidence skywave (NVIS) frequency predictions. Measured and predicted monthly median frequencies are compared, as are the upper and lower decile frequencies (10% and 90% respectively). The ASAPS basic MUF predictions generally agree with fxI (in lieu of fxF2) measurements, whereas those for VOACAP appear to be conservative for the Chilton ionosonde, particularly around solar maximum. Below ~4 MHz during winter nights around solar minimum, both ASAPS and VOACAP MUF predictions tend towards foF2, which is contrary to their underlying theory and requires further investigation. While VOACAP has greater errors at solar maximum, those for ASAPS increase at low or negative T-index values. Finally, VOACAP errors might be large when T-SSN exceeds ~15.

Antenna GT Degradation with Inefficient Receive Antenna at HF
This paper presents the antenna G/T degradation incurred when communications systems use very inefficient receive antennas. This work is relevant when considering propagation predictions at HF (2-30 MHz), where it is commonly assumed that antennas are efficient/lossless and external noise dominates over internally generated noise at the receiver. Knowledge of the antenna G/T degradation enables correction of potentially optimistic HF predictions. Simple rules of-thumb are provided to identify scenarios when receive signal-to-noise ratios might be degraded.

60 GHz F-Scan SIW Meanderline Antenna for Radar Applications
This paper describes the design and characterization of a frequency-scanning meanderline antenna for operation at 60 GHz. The design incorporates SIW techniques and slot radiating elements. The amplitude profile across the antenna aperture has been weighted to reduce sidelobe levels, which makes the design attractive for radar applications. Measured performance agrees with simulations, and the achieved beam profile and sidelobe levels are better than previously documented frequency-scanning designs at V and W bands.

Midlatitude 5 MHz HF NVIS Links: Predictions vs. Measurements
Signal power measurements for a UK-based network of three beacon transmitters and five receiving stations operating on 5.290 MHz were taken over a 23 month period between May 2009 and March 2011, when solar flux levels were low. The median signal levels have been compared with monthly median signal level predictions generated using VOACAP (Voice of America Coverage Analysis Program) and ASAPS (Advanced Stand Alone Prediction System) HF prediction software with the emphasis on the near-vertical incidence sky wave (NVIS) links. Low RMS differences between measurements and predictions for September, October, November, and also March were observed. However, during the spring and summer months (April to August), greater RMS differences were observed that were not well predicted by VOACAP and ASAPS and are attributed to sporadic E and, possibly, deviative absorption influences. Similarly,the measurements showed greater attenuation than was predicted for December, January, and February, consistent with the anomalously high absorption associated with the “winter anomaly.” The summer RMS differences were generally lower for VOACAP than for ASAPS. Conversely, those for ASAPS were lower during the winter for the NVIS links considered in this analysis at the recent low point of the solar cycle. It remains to be seen whether or not these trends in predicted and measured signal levels on 5.290 MHz continue to be observed through the complete solar cycle.

Electrically small monopoles: Classical vs. Self-Resonant
This paper shows that the Q-factor and VSWR of a monopole are significantly lowered when made resonant by reactive loading (as is used in practice). Comparison with a self-resonant Koch fractal monopole of equal height gives similar values of VSWR and Q-factor. Thus, the various electrically small monopoles (self-resonant and reactively loaded) offer comparable performance when ideal and lossless. However, in selecting the optimum design, conductor losses and mechanical construction at the frequency of interest must be considered. In essence, a trade-off is necessary to obtain an efficient, electrically small antenna suitable for the application in hand.

Ku-Band Low-Sidelobe Waveguide Array
The design of a 16-element waveguide array employing radiating T-junctions that operates in the Ku band is described. Amplitude weighting results in low elevation sidelobe levels, while impedance matching provides a satisfactory VSWR, that are both achieved over a wide bandwidth (15.7-17.2 GHz). Simulation and measurement results, that agree very well, are presented. The design forms part of a 16 x 40 element waveguide array that achieves high gain and narrow beamwidths for use in an electronic-scanning radar system.

5-50+ GHz Tapered-Slot Antenna for Handheld Devices
A lightweight, wideband tapered-slot antenna that uses an antipodal Vivaldi design and provides useable gain from ~5 GHz to in excess of 50 GHz is described. Simulations and measurements are presented that show excellent agreement. This antenna design is currently deployed in handheld test equipment.