

























SSL: The Revolution Will Not Be Supervised



Written by Jason Pompeus
Senior Data Scientist
SSL: The Revolution Will Not Be Supervised
Leveraging expertise across the RF sensing, communications, and low SWaP (size, weight and power) electronics domain spaces, Plextek delivers custom R&D and product development across a range of industries including consumer, healthcare, and defence.
To ensure we remain positioned to best support our customers’ needs, Plextek prides itself on continuous innovation, and the conscious application of new and emerging technologies.
This includes the rapidly evolving field of machine learning (ML), where Plextek has demonstrated interdisciplinary expertise in finding novel solutions to new and existing problems. Using image generation architectures to rapidly model radio frequency (RF) propagation, exploring the use of transformer self-attention for interpretable data fusion, and classifying and parameterising RF modulation schemes for electronic countermeasure tasks are some examples of such technologies that Plextek has applied to real-world problems.
Here we look at a new training paradigm for machine learning architectures – called Self-Supervised Learning – which has the potential to improve the accessibility of ML approaches to niche and under-represented domains, while simultaneously reducing the time and effort spent on dataset curation. We explore the motivation behind this technique, how it works, and how Plextek can use this technology to continue innovating in an ever-evolving landscape.


It’s a familiar paradigm of machine learning: if you want your model to perform – and to perform consistently – you need data, lots of it, and diverse enough to capture all the key features and corner cases your model will need to recognise once deployed. This volume of data needs also to be labelled. That is, the training framework needs to know a priori what each sample represents, to mark the model’s predictions as right or wrong, and to update its parameters accordingly. As models grow in complexity, so do they require vast and varied datasets, and so too do unlucky teams of analysts need to perform the laborious job of labelling it.
This method of training ML models on labelled datasets is known as supervised learning, and for expansive, increasingly multi-modal applications such as natural language processing, speech recognition, or generic object detection, the process of labelling your dataset can be a costly, tedious and time-consuming enterprise in its own right. But what if there were a way for your model to learn important features from the data without supervision, i.e. without labels? After all, human intelligence learns in large part from unsupervised observation of the world it inhabits – very young children, for example, learn their first words by listening to and imitating conversations around them, not from extensive and repeated lessons in grammar.
This is the core idea behind self-supervised learning (or SSL). SSL trains the model to learn useful features from an unlabeled dataset by maximising the similarities of internal representations of like data samples. Typically, this involves two neural networks operating in parallel – a student network and a teacher network – with matching architectures and shared weights.
By sharing weights, the networks are essentially twinned – given the same input sample, both the student and teacher would encode identical representations. However, during training, each network is presented with a different “view” of the same input sample, initially resulting in two unrelated representational encodings. A projection head at the output of each network maps the encodings back into a space where a contrastive loss function can be applied, and this loss function updates the weights of the student network to maximise the agreement between its output and that of the teacher. The new weights are then copied across to the teacher network, and after multiple iterations, the student learns a consistent encoding for the sample regardless of the “view” it has of it.
(Modern implementations perform a slightly more sophisticated approach, but the same general principle is followed).
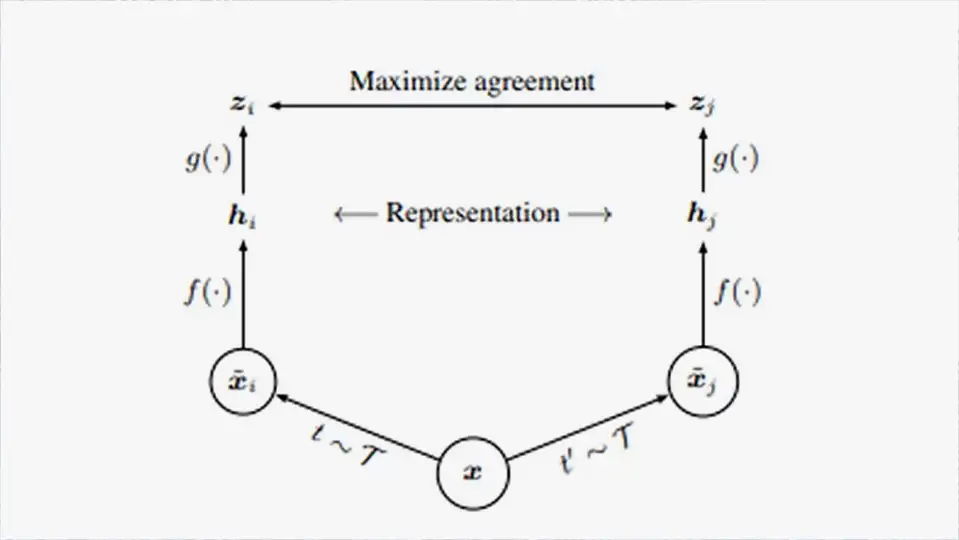
These “views” are generated by applying carefully chosen transforms to the data samples, that preserve the features of interest but change the context in which they appear. For example, for a large language model (LLM), the teacher may be presented with a sample sentence, and the student presented with the same sentence with one or more words removed. The student would then be tasked with “filling in the blank”, and in doing so is forced to learn the underlying language rules. In the field of computer vision, crops, rotations, and colour distortions are used to generate a transformed view of a sample image, again forcing the student network to learn the important features common to both instances.
Studies have shown that the quality of representations learned can be very sensitive to the choice of transform. Fortunately, a research team at Google was able to leverage its resources to perform a comprehensive study of image-based transforms, providing framework for efficient SSL for computer vision tasks called SimCLR [1].
Crucially, these pairs of sample views can be generated automatically, and with no explicit prior knowledge of the contents of the dataset (beyond an appropriate choice of transform). Further, feature learning is autonomous and task agnostic. Once the self-supervised portion of the training is complete, the teacher network and projection heads can be discarded, and the student network can be applied to the desired task via transfer learning. Here, a new classification layer (or layers) is appended to the network and trained on the task using a labelled dataset. However, having already learned suitable representational encodings during the SSL process, the final (supervised) learning step can be performed with far less labelled data.
SSL therefore presents a new training paradigm that can drastically reduce the cost and manpower that traditionally accompanies the training of complex models on large datasets. For Plextek, this means that more time can be spent on meaningful development, adding functionality and improving the quality of model output. SSL may also make domain-specialised problem spaces more accessible to machine learning approaches, where ordered datasets do not exist, or are under-represented amongst the open-source repositories available online. Underwater acoustics and an increasingly cluttered RF spectrum are two such challenging environments in which Plextek has a history of expertise, and where SSL techniques can not only increase the effective volume of usable training data, but also improve the quality of features learned. This in turn enables the development of powerful, custom ML applications, tailored to the needs of the customer.
Already, models trained under an SSL framework have been demonstrated to perform at an equivalent or better level than their classically trained counterparts. Recently, for example, an SSL method called DINO has been demonstrated by a research team at Meta AI [2], training a vision transformer (ViT) on image recognition tasks. Incredibly, they found that their model displayed an emergent capability for object segmentation, having learned to do so with no prior object labelling or masking.

Segmentations learned by equivalent ViT’s under supervised and self-supervised (DINO) learning frameworks
This surprising level of capability, arising naturally from autonomous learning, is one of the reasons SSL has been hailed the “dark matter of intelligence” by Meta’s VP and Chief AI Scientist Yann LeCun. A model’s ability to learn unassisted, by observation of the world around it, is a landmark step on the way to artificial general intelligence (AGI), allowing the model to develop an intuitive understanding of relationships and features within a dataset, before even being set to the desired end-task. This in turn better ensures that its decision-making output is grounded in analysis of the relevant features, making the model more robust to new contexts and environments, quicker to re-train on previously unseen classes, and, perhaps of more interest to those analysts, gives them a day off from labelling yet another endless dataset.
[1] A Simple Framework for Contrastive Learning of Visual Representations, Chen et al, 2020
[2] Emerging Properties in Self-Supervised Vision Transformers, Caron et al, 2021


Contact Us
Technology Platforms
Plextek's 'white-label' technology platforms allow you to accelerate product development, streamline efficiencies, and access our extensive R&D expertise to suit your project needs.
-
01 Configurable mmWave Radar Module
 Configurable mmWave Radar Module
Configurable mmWave Radar ModulePlextek’s PLX-T60 platform enables rapid development and deployment of custom mmWave radar solutions at scale and pace
-
02 Configurable IoT Framework
 Configurable IoT Framework
Configurable IoT FrameworkPlextek’s IoT framework enables rapid development and deployment of custom IoT solutions, particularly those requiring extended operation on battery power
-
03 Ubiquitous Radar
 Ubiquitous Radar
Ubiquitous RadarPlextek's Ubiquitous Radar will detect returns from many directions simultaneously and accurately, differentiating between drones and birds, and even determining the size and type of drone

Measuring Micro-Debris in LEO with Next-Gen Space Radar
Detecting micro-debris in real-time is key to safer space operations. Next-gen mmWave radar technology enables high-resolution tracking of even the smallest fragments in LEO, reducing collision risks and enhancing space situational awareness. Discover how this innovation supports a more sustainable orbital future.

The Future of Connectivity: 5G, 6G, and Space-Based Networks
As industries push the boundaries of global connectivity, the integration of 5G and drive towards 6G with satellite and space-based networks is unlocking new opportunities. Kevin Cobley, an expert in this evolving field, shares his insights on the challenges and innovations shaping the future of non-terrestrial networks (NTN).

Urban Challenges: Rapid RF Propagation Modelling
Discover the challenges and solutions for accurately modelling RF propagation in urban settings. Explore the innovative neural network model revolutionising urban RF systems.

Enhancing communication and safety in mining: the role of custom RF system design
We explore the role of custom RF system design in communication and safety within the mining industry, ensuring robust data handling and operational efficiency in challenging conditions.

SSL: The Revolution Will Not Be Supervised
Exploring the cutting-edge possibilities of Self-Supervised Learning (SSL) in machine learning architectures, revealing new potential for automatic feature learning without labelled datasets in niche and under-represented domains.

Evolving silicon choices in the AI age
How do you choose? We explore the complexities and evolution of processing silicon choices in the AI era, from CPUs and GPUs to the rise of TPUs and NPUs for efficient artificial intelligence model implementation.

Advancing space technology solutions through innovation
At the forefront of space technology innovation, we address complex engineering challenges in the sector, delivering low size, weight, and power solutions tailored for the harsh environment of space.

A Programmer’s Introduction to Processing Imaging Radar Data
A practical guide for programmers on processing imaging radar data, featuring example Python code and a detailed exploration of a millimetre-wave radar's data processing pipeline.

Using Artificial Intelligence to Explore the Biological World
Harnessing AI's capabilities to decode protein folding, catalysing a leap in biological research and therapeutic innovation.

Artificial Intelligence in the Big and Scary Real World
Analysing the application of Artificial Intelligence in real-world scenarios, addressing its transformative potential and the ethical framework required for its deployment.

Are there really any benefits to 5G?
Questioning the real-world benefits of 5G technology, offering a candid examination of its impact on connectivity and the disparity between expectations and user experiences.

AI Gesture Control
Exploring the possibilities of AI gesture control for household appliances and more, using privacy-preserving radar technology, underscoring innovation in smart home interactions.

Semantic Segmentation in Visual Scene Matching
Learn how we boost accuracy in Visual Scene Matching with Semantic Segmentation, aiding navigation and tracking in dynamic environments.
Read More
Machine Learning for Rapid Propagation Assessment
Developing a groundbreaking ML model for swift and efficient coverage prediction in complex urban environments, enabling rapid optimisation of transmitter locations on standard computing hardware.
Read More

Future Sensing: Improving Mobile Ad-hoc Networks
Leading a transformative four-year research initiative to improve mobile ad-hoc networks through advanced directional antenna systems and cross-layer processing, significantly enhancing military communication capabilities.
Read More

Communicating Across Surfaces
Using innovative expertise in metamaterials to facilitate the development of advanced surfaces, improving RF communication efficiency through pioneering surface wave technology for superior antenna design and wireless connectivity.
Read More

Armour Integrity Monitoring System (AIMS)
Innovating a new Armour Integrity Monitoring System (AIMS) for the UK MoD, delivering a low SWaP-C solution that dramatically streamlines logistics and enhances protection through in-field armour integrity checks.
Read More

mmWave Radar for Foreign Object Debris Detection
Collaborating with WaveTech to develop an advanced mmWave radar system, enabling the rapid and automated detection of foreign object debris on runways, enhancing safety and operational efficiency at a South Korean airport.
Read More

Developing Automated Manufacturing Systems
Delivering a pioneering predictive maintenance solution for a global healthcare product company, utilising miniature battery-powered sensor systems to optimise automated production lines and significantly reduce costly downtimes.
Read More

Surveillance Radar for Comprehensive Threat Detection
Advancing a perimeter surveillance solution with long-range detection and low false-alarm rates, using state-of-the-art Passive Electronically Scanned Array technology for robust and maintenance-free operation in a range of demanding environments.
Read More

Immersive Technology for Complex Systems Training
Using the latest immersive technologies to deliver realistic and engaging training solutions for complex systems, ensuring specialist procedures are effectively imparted and measured within any environment.
Read More
Distributed Real Time Spectrum Monitoring
Developing an innovative distributed spectrum monitoring system, using low-cost software-defined radio platforms, to provide superior interference detection and larger coverage for high-value sites.
Read More

Intelligent Mobility
Advancing intelligent mobility by integrating cutting-edge electronic-scanning radar technology to ensure the safe and efficient operation of autonomous vehicles in complex real-world environments.
Read More

Telehealth Innovation – Connecting Patients to their Carers
Revolutionising telehealth with the MonitorMe phone, seamlessly connecting patients to healthcare providers for vital signs monitoring.
Read More

mmWave Imaging Radar
Camera systems are in widespread use as sensors that provide information about the surrounding environment. But this can struggle with image interpretation in complex scenarios. In contrast, mmWave radar technology offers a more straightforward view of the geometry and motion of objects, making it valuable for applications like autonomous vehicles, where radar aids in mapping surroundings and detecting obstacles. Radar’s ability to provide direct 3D location data and motion detection through Doppler effects is advantageous, though traditionally expensive and bulky. Advances in SiGe device integration are producing more compact and cost-effective radar solutions. Plextek aims to develop mm-wave radar prototypes that balance cost, size, weight, power, and real-time data processing for diverse applications, including autonomous vehicles, human-computer interfaces, transport systems, and building security.

Low Cost Millimeter Wave Radio frequency Sensors
This paper presents a range of novel low-cost millimeter-wave radio-frequency sensors that have been developed using the latest advances in commercially available electronic chip-sets. The recent emergence of low-cost, single chip silicon germanium transceiver modules combined with license exempt usage bands is creating a new area in which sensors can be developed. Three example systems using this technology are discussed, including: gas spectroscopy at stand off distances, non-invasive dielectric material characterization and high performance micro radar.
Ku-Band Metamaterial Flat-Panel Antenna for Satcom
This technical paper by Dr. Rabbani and his team presents research on metamaterial-based, high-gain, flat-panel antennas for Ku-band satellite communications. The study focuses on leveraging the unique electromagnetic properties of metamaterials to enhance the performance of flat-panel antenna designs, aiming for compact structures with high gain and efficiency. The research outlines the design methodology involving multi-layer metasurfaces and leaky-wave antennas to achieve a compact antenna system with a realised gain greater than +20 dBi and an operational bandwidth of 200 MHz. Simulations results confirm the antenna's high efficiency and performance within the specified Ku-band frequency range. Significant findings include the antenna's potential for application in low-cost satellite communication systems and its capabilities for THz spectrum operations through design modifications. The paper provides a detailed technical roadmap of the design process, supported by diagrams, simulation results, and references to prior work in the field. This paper contributes to the advancement of antenna technology and metamaterial applications in satellite communications, offering valuable insights for researchers and professionals in telecommunications.

The Kootwijk VLF Antenna: A Numerical Model
A comprehensive analysis of the historical Kootwijk VLF (Very Low Frequency, which covers 3-30 kHz) antenna, including the development of a numerical model to gain insight into its operation. The Kootwijk VLF antenna played a significant role in long-range communication during the early 20th century. The paper addresses the challenge of accurately modelling this electrically small antenna due to limited historical technical information and its complex design. The main goal is to understand if the antenna’s radiation efficiency might explain why “results were disappointing” for the Kootwijk to Malabar (Indonesia) communications link. Through simulations and comparisons with historical records, the numerical model reveals that the Kootwijk VLF antenna had a low radiation efficiency – about 8.9% – for such a long-distance link. This work discusses additional loss mechanisms in the antenna system that might not have been considered previously, including increased transmission-line losses as a result of impedance mismatch, wires having a lower effective conductivity than copper and inductor quality factors being lower than expected. The study provides insights into key antenna parameters, such as the radiation pattern, the antenna’s quality factor, half-power bandwidth and effective height, as well as the radiated power level and the power lost through dissipation. This research presents the first documented numerical analysis of the Kootwijk VLF antenna and contributes to a better understanding of its historical performance. While the focus has been at VLF, this work can aid future modelling efforts for electrically small antennas at other frequency bands.

The Radiation Resistance of Folded Antennas
This technical paper highlights the ambiguity in the antenna technical literature regarding the radiation resistance of folded antennas, such as the half-wave folded dipole (or quarter-wave folded monopole), electrically small self-resonant folded antennas and multiple-tuned antennas. The feed-point impedance of a folded antenna is increased over that of a single-element antenna but does this increase equate to an increase in the antenna’s radiation resistance or does the radiation resistance remain effectively the same and the increase in feed-point impedance is due to transformer action? Through theoretical analysis and numerical simulations, this study shows that the radiation resistance of a folded antenna is effectively the same as its single-element counterpart. This technical paper serves as an important point of clarification in the field of folded antennas. It also showcases Plextek's expertise in antenna theory and technologies. Practitioners in the antenna design field will find valuable information in this paper, contributing to a deeper understanding of folded antennas.

Chilton Ionosonde Data & HF NVIS Predictions during Solar Cycle 23
This paper presents a comparison of Chilton ionosonde critical frequency measurements against vertical-incidence HF propagation predictions using ASAPS (Advanced Stand Alone Prediction System) and VOACAP (Voice of America Coverage Analysis Program). This analysis covers the time period from 1996 to 2010 (thereby covering solar cycle 23) and was carried out in the context of UK-centric near-vertical incidence skywave (NVIS) frequency predictions. Measured and predicted monthly median frequencies are compared, as are the upper and lower decile frequencies (10% and 90% respectively). The ASAPS basic MUF predictions generally agree with fxI (in lieu of fxF2) measurements, whereas those for VOACAP appear to be conservative for the Chilton ionosonde, particularly around solar maximum. Below ~4 MHz during winter nights around solar minimum, both ASAPS and VOACAP MUF predictions tend towards foF2, which is contrary to their underlying theory and requires further investigation. While VOACAP has greater errors at solar maximum, those for ASAPS increase at low or negative T-index values. Finally, VOACAP errors might be large when T-SSN exceeds ~15.

Antenna GT Degradation with Inefficient Receive Antenna at HF
This paper presents the antenna G/T degradation incurred when communications systems use very inefficient receive antennas. This work is relevant when considering propagation predictions at HF (2-30 MHz), where it is commonly assumed that antennas are efficient/lossless and external noise dominates over internally generated noise at the receiver. Knowledge of the antenna G/T degradation enables correction of potentially optimistic HF predictions. Simple rules of-thumb are provided to identify scenarios when receive signal-to-noise ratios might be degraded.

60 GHz F-Scan SIW Meanderline Antenna for Radar Applications
This paper describes the design and characterization of a frequency-scanning meanderline antenna for operation at 60 GHz. The design incorporates SIW techniques and slot radiating elements. The amplitude profile across the antenna aperture has been weighted to reduce sidelobe levels, which makes the design attractive for radar applications. Measured performance agrees with simulations, and the achieved beam profile and sidelobe levels are better than previously documented frequency-scanning designs at V and W bands.

Midlatitude 5 MHz HF NVIS Links: Predictions vs. Measurements
Signal power measurements for a UK-based network of three beacon transmitters and five receiving stations operating on 5.290 MHz were taken over a 23 month period between May 2009 and March 2011, when solar flux levels were low. The median signal levels have been compared with monthly median signal level predictions generated using VOACAP (Voice of America Coverage Analysis Program) and ASAPS (Advanced Stand Alone Prediction System) HF prediction software with the emphasis on the near-vertical incidence sky wave (NVIS) links. Low RMS differences between measurements and predictions for September, October, November, and also March were observed. However, during the spring and summer months (April to August), greater RMS differences were observed that were not well predicted by VOACAP and ASAPS and are attributed to sporadic E and, possibly, deviative absorption influences. Similarly,the measurements showed greater attenuation than was predicted for December, January, and February, consistent with the anomalously high absorption associated with the “winter anomaly.” The summer RMS differences were generally lower for VOACAP than for ASAPS. Conversely, those for ASAPS were lower during the winter for the NVIS links considered in this analysis at the recent low point of the solar cycle. It remains to be seen whether or not these trends in predicted and measured signal levels on 5.290 MHz continue to be observed through the complete solar cycle.

Electrically small monopoles: Classical vs. Self-Resonant
This paper shows that the Q-factor and VSWR of a monopole are significantly lowered when made resonant by reactive loading (as is used in practice). Comparison with a self-resonant Koch fractal monopole of equal height gives similar values of VSWR and Q-factor. Thus, the various electrically small monopoles (self-resonant and reactively loaded) offer comparable performance when ideal and lossless. However, in selecting the optimum design, conductor losses and mechanical construction at the frequency of interest must be considered. In essence, a trade-off is necessary to obtain an efficient, electrically small antenna suitable for the application in hand.

Ku-Band Low-Sidelobe Waveguide Array
The design of a 16-element waveguide array employing radiating T-junctions that operates in the Ku band is described. Amplitude weighting results in low elevation sidelobe levels, while impedance matching provides a satisfactory VSWR, that are both achieved over a wide bandwidth (15.7-17.2 GHz). Simulation and measurement results, that agree very well, are presented. The design forms part of a 16 x 40 element waveguide array that achieves high gain and narrow beamwidths for use in an electronic-scanning radar system.

5-50+ GHz Tapered-Slot Antenna for Handheld Devices
A lightweight, wideband tapered-slot antenna that uses an antipodal Vivaldi design and provides useable gain from ~5 GHz to in excess of 50 GHz is described. Simulations and measurements are presented that show excellent agreement. This antenna design is currently deployed in handheld test equipment.
Downloads
View All Downloads- PLX-T60 Configurable mmWave Radar Module
- PLX-U16 Ubiquitous Radar
- Configurable IOT Framework
- Cost Effective mmWave Radar Devices
- Connected Autonomous Mobility
- Antenna Design Services
- Drone Sensor Solutions for UAV & Counter-UAV Awareness
- mmWave Sense & Avoid Radar for UAVs
- Exceptional technology for marine operations